Jagger - C++ implementation of Pattern-based Japanese Morphological Analyzer
About
Jagger は、辞書に基づく単語分割のための最長一致法と、機械学習の分類器の事前計算に着想を得た、特徴パターンに基づく高速・高精度・省メモリの形態素解析器[1]です。Jagger は形態素解析辞書や学習コーパスから抽出したパターンを入力テキストの先頭から適用し、同時かつ決定的に単語の分割位置、切り出した単語の品詞、見出し語を決定します。最小コスト法や点推定などに基づく既存の効率的な形態素解析器[2,3]と遜色ない解析精度で、1CPUで340万文(8800万語)/秒を超える速度で形態素解析を行うことができます(M4 MacBook Air上)。
Jagger を学術・商用利用する方は以下の参考文献を引用ください。
Naoki Yoshinaga
Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie
The 61st Annual Meeting of the Association for Computational Linguistics (ACL-23). Toronto, Canada. July 2023
開発の経緯に興味がある方は
Naoki Yoshinaga
記号処理への回帰:パターンに基づく速度指向言語処理
自然言語処理.30巻4号 p. 1266-1271. 2023.
をどうぞ。実装の詳細は
Yahoo! JAPAN での招待講演の資料で少し触れています。
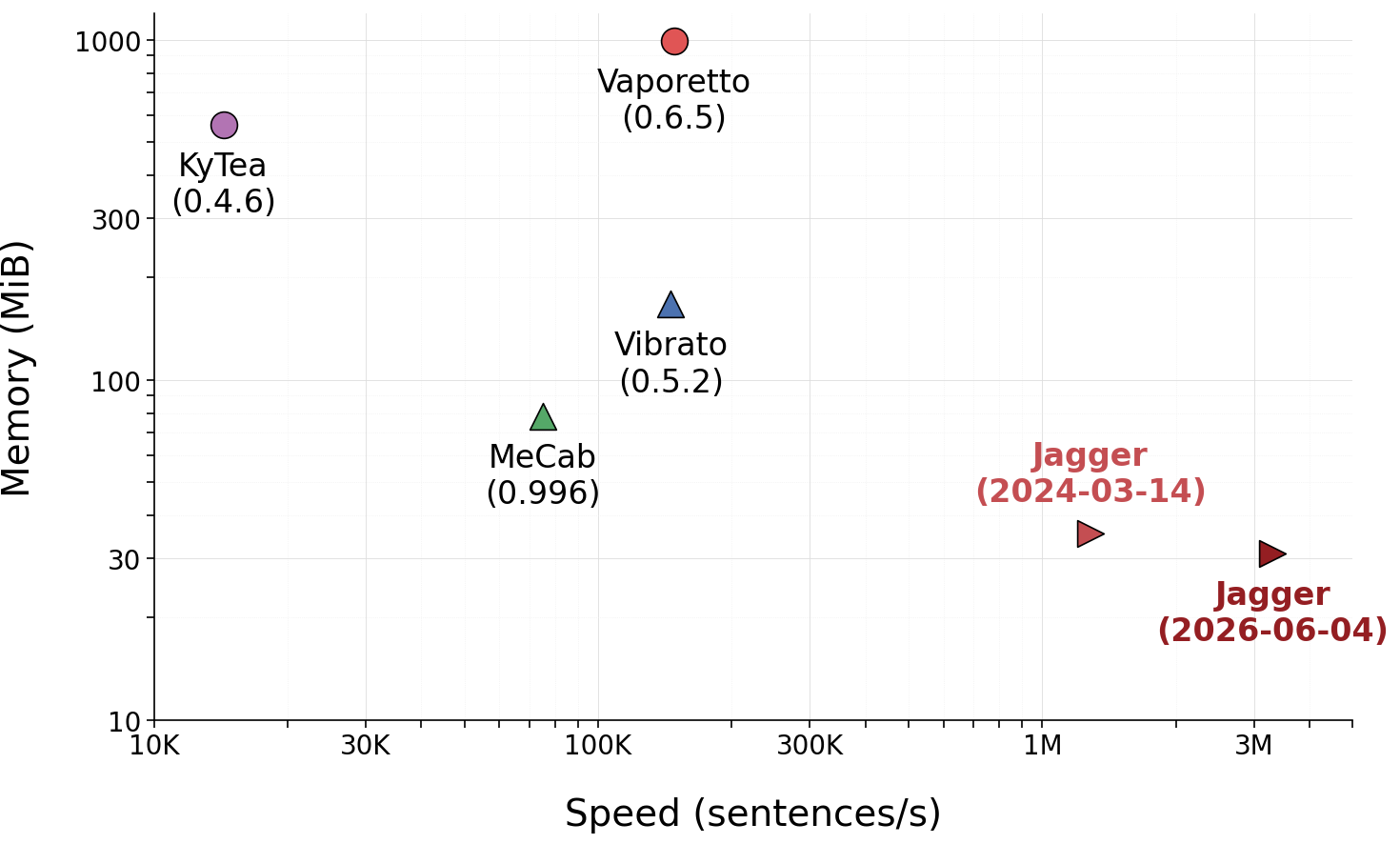
形態素解析器の速度と消費メモリの比較(京都大学テキストコーパス, 辞書: jumandic-7.0-20130310, M4 MacBook Air + clang 21)
Features
License: GNU GPLv2, LGPLv2.1, BSD
Download & Setup
> wget http://www.tkl.iis.u-tokyo.ac.jp/~ynaga/jagger/jagger-latest.tar.gz
> tar zxvf jagger-latest.tar.gz
> cd jagger-YYYY-MM-DD
# 1) mecab-jumandic 形式の辞書を用意 (cf. mecab-jumandic-7.0-20130310.tar.gz)
> tar zxvf mecab-jumandic-7.0-20130310.tar.gz
> patch -p0 < mecab-jumandic-7.0-20130310.patch # 助動詞の文字化けを修正
# 2) 京都大学ウェブ文書リード文コーパスを用いる場合 (デフォルト)
> git clone https://github.com/ku-nlp/KWDLC
> configure
# 2') または、京都大学テキストコーパスを用いる場合
> git clone https://github.com/ku-nlp/KyotoCorpus
> cd KyotoCorpus; auto_conv -d PATH_TO_MAINICHI_NEWS_DIR; cd ..
> configure --with-corpus=kyoto
# 3) 標準分割からモデルを学習し、評価も行った上でインストール
> make model-benchmark && make install
# 3') 自分で用意した形態素解析辞書、注釈付き学習データ、評価データを用いて学習・評価を行う場合
> make install
> train_jagger -d DICT_FILE TRAIN_FILE_WITH_POS > PATTERN_DIR/patterns
> jagger -m PATTERN_DIR [-w] < TEST_FILE > result.JAG
> eval.py result.JAG TEST_FILE_WITH_POS
言語資源の入手先:
ToDo
- ユーザ定義パターンの動的追加
- パターンテンプレートの洗練による高精度化(やる気次第)
- 部分アノテーションからの学習(かんたん)
- 静的ダブル配列の採用による高速・省メモリ化(難しい)
- 係り受け解析器 J.DepP への統合
History
- June 27th, 2026 (開発版; 微修正・更新する可能性あり):
- データ構造の改良と探索のキャッシュによりパターンの学習を最大5倍高速化しつつメモリ消費を1/3まで削減
- 前品詞を含むパターンの枝刈りのバグを修正(解析精度・速度を僅かに改善)
- June 4th, 2026:
- データ構造の改良と出力の効率化により解析を最大2.5倍高速化(+省メモリ・ディスク化)
- clang 21 でコンパイルしたときに起きる stack overflow (ccedar_core.h) を修正
- configure 時の
--enable-compact-dict オプションの廃止
- コードの可読性の改善・簡素化
- March 14th, 2024:
- 絵文字など記号に関する未知語処理を追加
- ユーザ定義辞書のサポート
- 無限長入力(改行のない入力)の解析をサポート
- パターン学習時のメモリ消費を半減
-f オプション (jagger)の廃止(::isatty (0) == 0) のとき full buffering を有効化)- パターンのコンパイルを推論時から学習時に変更
- 未知語の見出し語の出力に関するバグ修正
- メモリ周りの細かいバグ修正
- コードの可読性の改善・簡素化
- February 18th, 2023:
Usage
Tagging
コマンドラインで jagger -h とタイプすると、以下の usage が表示されます。デフォルトではインストール時に指定した辞書とコーパスから学習したモデルを読み込みます。
jagger: Pattern-based Japanese Morphological Analyzer
Copyright (c) 2023-present Naoki Yoshinaga. All rights reserved.
Usage: src/jagger [OPTIONS] < input
Options:
-m DIR Directory for compiled patterns (default: JAGGER_DEFAULT_MODEL)
-w Perform only segmentation
-w オプションをつけて実行すると、単語分割のみを行います。
Training
コマンドラインで train_jagger とタイプすると、以下の usage が表示されます。
train_jagger: Extract patterns for Jagger from dictionary and training data
Copyright (c) 2023-present Naoki Yoshinaga. All rights reserved.
Usage: src/train_jagger [OPTIONS] train
Options:
-m DIR Directory to store patterns
-d FILE Dictionary file in CSV format
-u FILE User-defined dictionary file in CSV format
dict, user_dict は MeCab (jumandic) 形式の辞書ファイルです(コスト等は無視されます。フィールド数さえ合っていれば良く、0で埋めて良い)。train は Jagger (MeCab) の出力と同じ形式の品詞タグ付きデータです。
How to add user-defined patterns
旧バージョンを使うか、パターンに対応する部分学習データ(対象とする形態素と前後文脈のみ学習事例を含む)を train_jagger に与えてください。将来的には(簡潔な実装を思いつけば)、推論時にパターンを動的に変更する機能を追加する予定です。
Performance Comparison
古いリリースとの比較については参考文献 [1]を確認ください。
Third-Party Contributions
C++ 以外のプログラミング言語で Jagger を使いたい方のためのポートやバインディング(ラッパー)には以下があります。
Disclaimer
文献 [1] で提案したアルゴリズムを除き、他の高速化手法については、特許が取得されていないかどうかは未確認です。どの手法も既存の OSS で広く実装・利用されているものなので、問題はないだろうと思いますが、本ソフトウェアを商用利用する際は、各自の責任でご使用ください。
Acknowledgments
本研究は JSPS 科研費 JP21H03494 および JST CREST JPMJCR19A4 の助成を受けたものです。2026年に公開した新版は、LINEヤフー株式会社との共同研究の支援を受けています。
References
- Naoki Yoshinaga. Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie. ACL-23. 2023
- Taku Kudo and Yuji Matsumoto. Applying Conditional Random Fields to Japanese Morphological Analysis. EMNLP-04. 2004
- Graham Neubig, Yosuke Nakata, and Shinsuke Mori. Pointwise Prediction for Robust, Adaptable Japanese Morphological Analysis. ACL-11. 2011
Copyright © 2023 Naoki Yoshinaga, All right Reserved.
last-modified: Jun 28 09:48:26 2026, written by
XHTML 1.1