Jagger - C++ implementation of Pattern-based Japanese Morphological Analyzer
About
Jagger is a fast, accurate, and space-efficient morphological analyzer [1] inspired by the dictionary-based longest matching for tokenization and the precomputation of machine-learning classifiers. Jagger applies patterns, which are extracted from morphological dictionaries and training data, to input from the beginning to simultaneously and deterministically perform tokenization, POS tagging, and lemmatization. Jagger can process more than 3.4 million sentences (88 million words) per second on a single CPU (M4 MacBook Air) with an accuracy comparable to existing practical implementations of morphological analyzers based on the Viterbi algorithm [2] and pointwise estimation [3].
If you make use of Jagger for research or commercial purposes, the reference will be:
Naoki Yoshinaga
Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie
The 61st Annual Meeting of the Association for Computational Linguistics (ACL-23). Toronto, Canada. July 2023
Refer to the slide and poster presented at ACL-23 for details of algorithms.
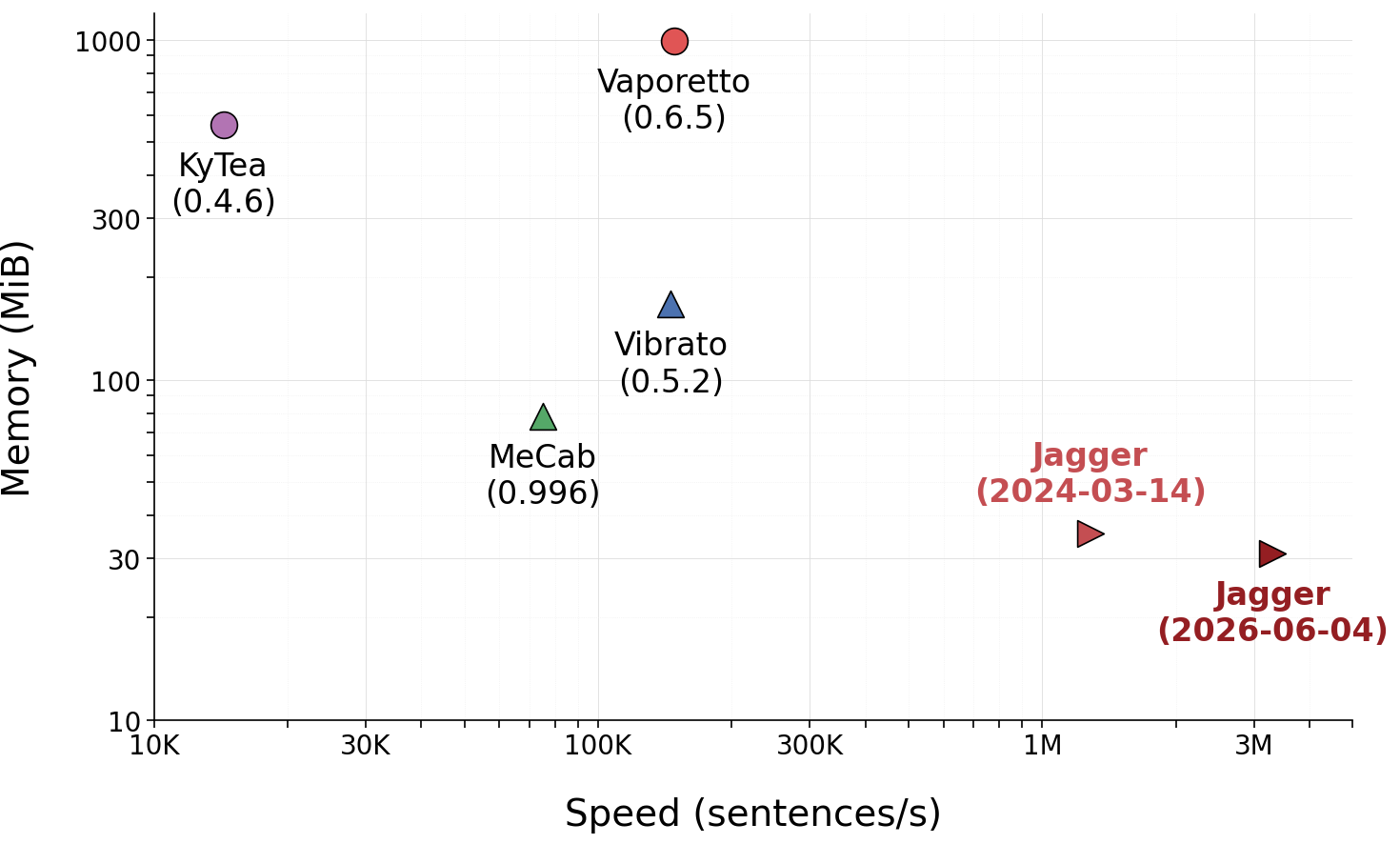
Comparison among morphonolgical anzlyzers (Kyoto University Text Corpus, dictionary: jumandic-7.0-20130310, M4 MackBook Air + clang 21)
Features
License: GNU GPLv2, LGPLv2.1, BSD
Download & Setup
> wget http://www.tkl.iis.u-tokyo.ac.jp/~ynaga/jagger/jagger-latest.tar.gz
> tar zxvf jagger-latest.tar.gz
> cd jagger-YYYY-MM-DD
# 1) prepare a dictionary in the format compatible with mecab-jumandic (cf. mecab-jumandic-7.0-20130310.tar.gz)
> tar zxvf mecab-jumandic-7.0-20130310.tar.gz
> patch -p0 < mecab-jumandic-7.0-20130310.patch # correct corrupted characters in AuxV.csv
# 2) Use the Kyoto University Web Document Leads Corpus (default)
> git clone https://github.com/ku-nlp/KWDLC
> configure
# 2') Or use the Kyoto University Text Corpus
> git clone https://github.com/ku-nlp/KyotoCorpus
> cd KyotoCorpus; auto_conv -d PATH_TO_MAINICHI_NEWS_DIR; cd ..
> configure --with-corpus=kyoto
# 3) Train a model from the standard split, evaluate the resulting model, and then install
> make model-benchmark && make install
# 3') To train a model using your own morphological dictionary and training data and then evaluate the resulting model on your test data
> make install
> train_jagger -d DICT_FILE TRAIN_FILE_WITH_POS > PATTERN_DIR/patterns
> jagger -m PATTERN_DIR [-w] < TEST_FILE > result.JAG
> eval.py result.JAG TEST_FILE_WITH_POS
Available resources:
ToDo
- Support dynamic addition of user-defined patterns
- Elaborating the pattern template for better accuracy (depends on my willingness)
- Training from partial annotations (easy)
- Using a static double array to make Jagger faster and more compact (hard)
- Integrating Jagger into an efficient dependency parser, J.DepP
History
- June 27th, 2026 (under development; subject to minor bugs, typos, comment fixes):
- Up to 5x speedup and 1/3 memory footprint in learning patterns via refined data structures and cached exploration
- Fix a bug in pruning patterns with previous POS (slight accuracy improvements with speedup)
- June 4th, 2026:
- Up to 2.5x speedup in decoding (and smaller memory/disk footprint) via refined data structures and optimized output
- Resolve stack overflow in cedar_core.h when compiling with clang 21
- Remove
--enable-compact-dict option from configure
- Simplify code for better readability
- March 14th, 2024:
- Add handling of unknown words on symbols (Emoji etc.)
- Support user-defined dictionary
- Support processing of unbounded input (without newline)
- Reduce the memory footprint in training
- Remove
-f option in jagger (enable full buffering if ::isatty (0) == 0)
- Move compilation of patterns from testing to training
- Fix a bug in printing lemma for unknown words
- Fix minor bugs related to memory access
- Simplify code for better readability
- February 18th, 2023:
Usage
Tagging
Typing jagger -h in the command line shows the following usage. By default, Jagger reads the model trained with the dictionary and training data specified at the installation.
jagger: Pattern-based Japanese Morphological Analyzer
Copyright (c) 2023-present Naoki Yoshinaga. All rights reserved.
Usage: src/jagger [OPTIONS] < input
Options:
-m DIR Directory for compiled patterns (default: JAGGER_DEFAULT_MODEL)
-w Perform only segmentation
If you add the -w option, Jagger performs only tokenization.
Training
Typing train_jagger in the command line will show the following usage.
train_jagger: Extract patterns for Jagger from dictionary and training data
Copyright (c) 2023-present Naoki Yoshinaga. All rights reserved.
Usage: src/train_jagger [OPTIONS] train
Options:
-m DIR Directory to store patterns
-d FILE Dictionary file in CSV format
-u FILE User-defined dictionary file in CSV format
dict, user_dict are dictionaries in the format compatible with MeCab (jumandic); note that Jagger will ignore cost parameters etc. You may want to fill them with 0; the number of fields just matters. train should be an annotated corpus in the same format as Jagger (MeCab)'s outputs.
How to add user-defined patterns
Please either use an older version or provide partially annotated training examples that include the target morpheme and its surrounding context to train_jagger. I plan to add functionality for dynamically modifying patterns at inference time in the future.
Performance Comparison
See the reference [1] for the comparison on the pre-release version.
Third-Party Contributions
For those who want to use Jagger in programming languages other than C++, the following third-party contributions to ports and bindings (wrappers) are available.
Disclaimer
Except for the algorithm proposed in [1], we have not verified whether the other optimization techniques are free from patent restrictions. Since these techniques are widely implemented in existing open-source software, we believe there should be no practical issues; however, please use this software at your own risk, especially for commercial purposes.
Acknowledgments
The development of this software is partially supported by JSPS KAKENHI Grant Number JP21H03494 and JST CREST JPMJCR19A4, Japan. The new versions released in 2026 is supported by a joint research project with LY Corporation.
References
- Naoki Yoshinaga. Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie. ACL-23. 2023
- Taku Kudo and Yuji Matsumoto. Applying Conditional Random Fields to Japanese Morphological Analysis. EMNLP-04. 2004
- Graham Neubig, Yosuke Nakata, and Shinsuke Mori. Pointwise Prediction for Robust, Adaptable Japanese Morphological Analysis. ACL-11. 2011
Copyright © 2023-present Naoki Yoshinaga, All rights reserved.
last-modified: Jun 28 09:47:59 2026, written by
XHTML 1.1