超大規模データ時代のための先進的データベースコア技術の研究
超大規模データ時代に向けて、かつてない高速性、省エネルギー性等を可能とする新たなデータベースコア技術の創出に取り組んでいます。データベースシステム、ストレージシステム、オペレーティングシステム等のシステムソフトウェアを中心に据えつつ、先進的な応用ソフトウェアとの融合にも挑戦しています。近年は、新型ソフトウェア実行原理に基づく超高速データベースエンジンの開発に成功しました。当該データベースエンジンは、徐々に社会の様々な場に於ける実用化が進んでいます。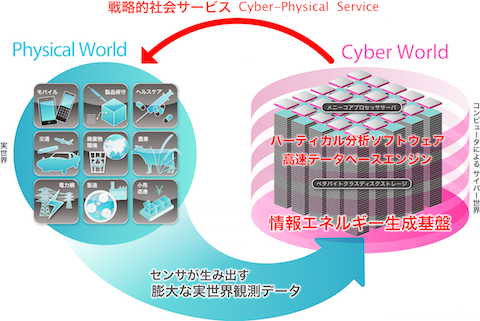

超大規模サイバー空間・実世界データのインタラクティブ解析システム
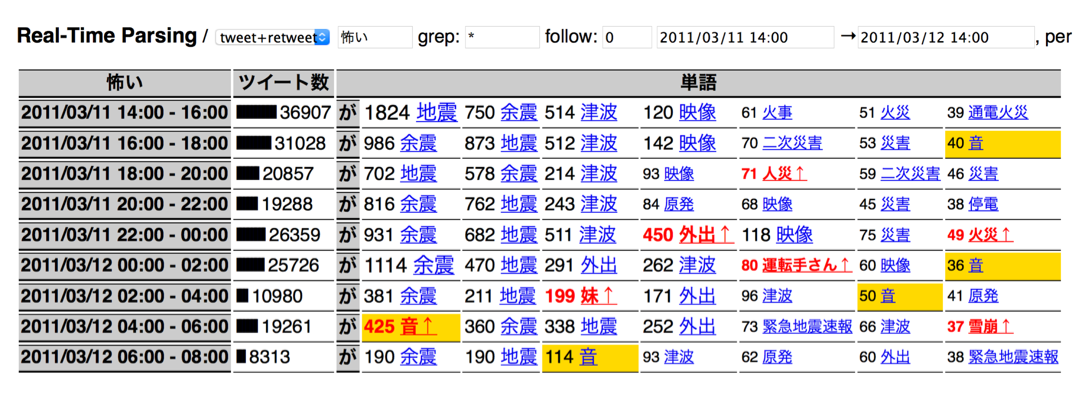
ウェブ・ソーシャルメディア等のサイバー空間と実世界は密接に連動しており、サイバー空間と実世界センサデータの融合解析による社会課題解決を目標とした研究を推進しています。1999年から継続的に日本語ウェブページを大規模収集し、数百億URL、数十億ブログ記事、Twitterの数百億つぶやき等を含む ウェブアーカイブを構築するとともに、ドライブレコーダデータ、交通トラフィックデータ、気象データ等の実世界データの収集・蓄積を行い、その構造、内容、時間変化等を解析するシステムを開発中です。膨大なサイバー空間・実世界データを、データマイニング、機械学習、リンク解析、自然言語処理、画像処理等を用いて解析し、様々な切り口で探索可能な可視化システムを大規模ディスプレイウォール上に実装しています。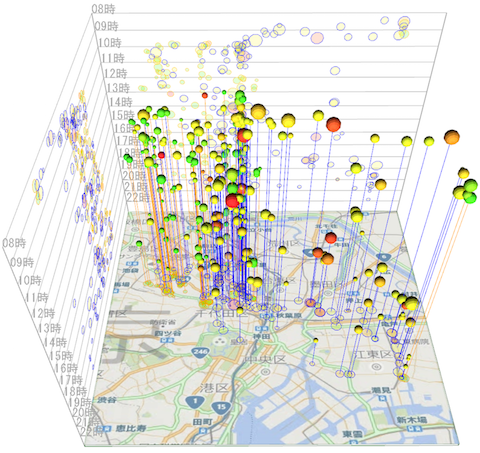

世に溢れることばを読み解き,新たに生み出す自然言語処理技術
人は言語を基に考え、社会での体験を記録し、他人に伝えることができます。本研究室では、人が紡ぐ無数の言葉からその心と社会の動きを読み解き、さらに人が行う様々な言語活動を代替・支援することを目指し、ことばを速く、正しく「計算」する工学的研究(自然言語処理)に広く取り組んでいます。最速・最小・最高精度のモデルの追求が、ときに確率的にときに規則正しく振る舞う自然現象としての言語の「かたち」に迫る理学的研究(計算言語学)、究極的には、人間の知能の働きの解明やその改善に繋がると考えている。
具体的には、計算機科学的方法論を駆使した世界最速の基礎解析技術やマイクロブログから新事物の出現・消滅を即時的に検知する実世界モニタリング技術を開発している。また大規模言語モデルの適応性・可搬性を高めるべく、解明したモデルの内部機序に基づくモデルの圧縮・分解・合成、知識を補う検索拡張生成、話者や使用環境(言語・時空間)、画像・音声まで視野に入れたマルチモーダル多言語モデル、さらに大規模言語モデルを用いた人の模倣の研究を進めている。

ペタバイト級地球環境情報融合システム
多種多様かつ膨大な地球観測データを統合・解析することにより、科学的・社会的に有用な情報に変換するアプリケーションのためのプラットフォームの構築を進めています。 大規模データアーカイブ、メタデータ管理、高性能データ解析処理、ビジュアライゼーション等に関する技術の研究開発に加え、長期的安定的なシステム運用、国際的な地球環境ポータルの構築にも取り組んでいます。 堅牢なデータベースと巨大な解析空間を有し、多分野からの莫大な量の地球環境データが蓄積されているだけでなく、さまざまなデータ処理・解析ツールも用意された統合的データ基盤を目指しています。