Research on Novel Database Core Technologies for the Era of Big Data
Our research group has been exploring and developing novel database core technologies for enabling Big Data management and analytics at a scale, a depth and efficiency that were ever thought to be impossible. The endeavor focuses on systems software such as database systems, storage systems and operating systems, but is not limited to them; the group also ventures to the fusion of infrastructure systems and cutting-edge social and business applications. One of the recent work is a super-fast database engine that the group successfully developed based on a novel execution principle. This brand-new engine is being deployed into more production systems in the market.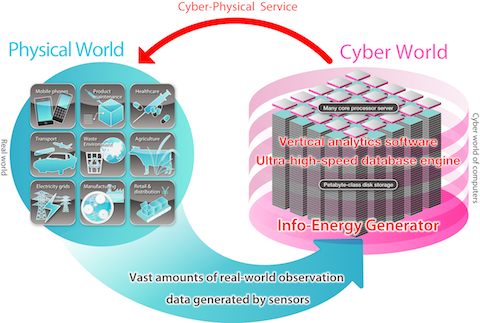

Very Large scale web solutions
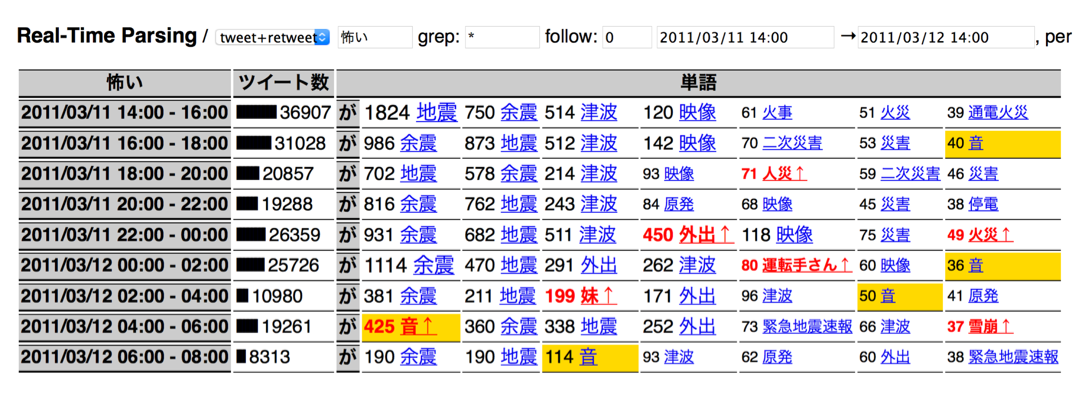
ウェブ・ソーシャルメディア等のサイバー空間と実世界は密接に連動しており、サイバー空間と実世界センサデータの融合解析による社会課題解決を目標とした研究を推進しています。1999年から継続的に日本語ウェブページを大規模収集し、数百億URL、数十億ブログ記事、Twitterの数百億つぶやき等を含む ウェブアーカイブを構築するとともに、ドライブレコーダデータ、交通トラフィックデータ、気象データ等の実世界データの収集・蓄積を行い、その構造、内容、時間変化等を解析するシステムを開発中です。膨大なサイバー空間・実世界データを、データマイニング、機械学習、リンク解析、自然言語処理、画像処理等を用いて解析し、様々な切り口で探索可能な可視化システムを大規模ディスプレイウォール上に実装しています。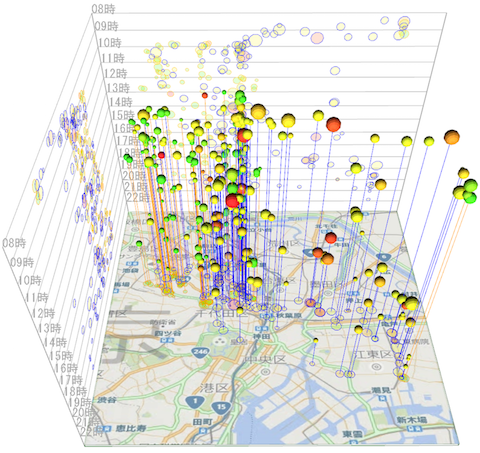

Natural Language Processing (NLP) for reading all languages in the wild and speaking as humans
Languages enable us to think, record experiences, and communicate. Our laboratory explores efficient and accurate natural language processing (NLP) to understand the human mind and society through countless words and support various language activities. The pursuit of fast, compact, and accurate models reveals the “shape” of language, as a natural phenomenon, that behaves both probabilistically and regularly (computational linguistics), ultimately leading to the understanding and refinement of human intelligence.
Specifically, we are developing the world’s fastest NLP data structures and algorithms from computer science, and real-world monitoring technologies that can instantly detect the emergence and disappearance of new entities from microblogs. We are also working to improve the adaptability and portability of large language models (LLMs) through techniques such as model compression, decomposition, and synthesis based on revealed insights into their internal mechanisms; retrieval-augmented generation to supplement knowledge; and multimodal, multilingual models that take into account speakers, usage environments (language, time, and space), as well as images and audio. Additionally, we are exploring the use of large language models in human imitation studies.

Petabyte-class global environment digital library
多種多様かつ膨大な地球観測データを統合・解析することにより、科学的・社会的に有用な情報に変換するアプリケーションのためのプラットフォームの構築を進めています。 大規模データアーカイブ、メタデータ管理、高性能データ解析処理、ビジュアライゼーション等に関する技術の研究開発に加え、長期的安定的なシステム運用、国際的な地球環境ポータルの構築にも取り組んでいます。 堅牢なデータベースと巨大な解析空間を有し、多分野からの莫大な量の地球環境データが蓄積されているだけでなく、さまざまなデータ処理・解析ツールも用意された統合的データ基盤を目指しています。 [詳細]